Last year, I undertook a project to autonomously map zebra crossings throughout Poland. The goal: make OpenStreetMap data more complete and improve pedestrian safety. In this post, I’ll detail the project’s process, results, and key takeaways.
As an OsmAnd navigation app user, I really enjoy the pedestrian crossing alerts feature. It increases my attention to the incoming crossings, and lets me better plan my drive. These alerts enhance safety, but require accurate underlying map data. By automating the mapping process, I could once and for all improve the crossing data across whole Poland.
Screenshot from https://osmand.net/docs/user/widgets/nav-widgets/#alert-widget
I suspected this was a prime use-case for machine learning, specifically YOLO object detection. However, I wanted to minimize the time spent labeling data - it’s a tedious and boring task. My solution was to train two models: a YOLO model to detect potential regions of interest (producing low confidence results), and a CNN for high-fidelity classification of zebra crossings. Since binary classification is significantly faster to label than object detection, this would save me time in the data preparation stage. I will use a self-hosted instance of CVAT for labeling - because I want to try out a new tool.
To collect the training data, I wrote a Python script to conveniently fetch existing mapped crossings data from OpenStreetMap, along with their corresponding governmental orthophotos.
Using OpenCV, a popular open-source computer vision library, I applied contrast enhancement and noise reduction to the obtained orthophotos. This pre-processing step improved the visibility of zebra crossings. Below, you can see a comparison of the original orthophoto (on the left) and the preprocessed one (on the right).

Annotating a single crossing took me around 10 seconds, resulting in a labeling speed of about 6 crossings per minute.
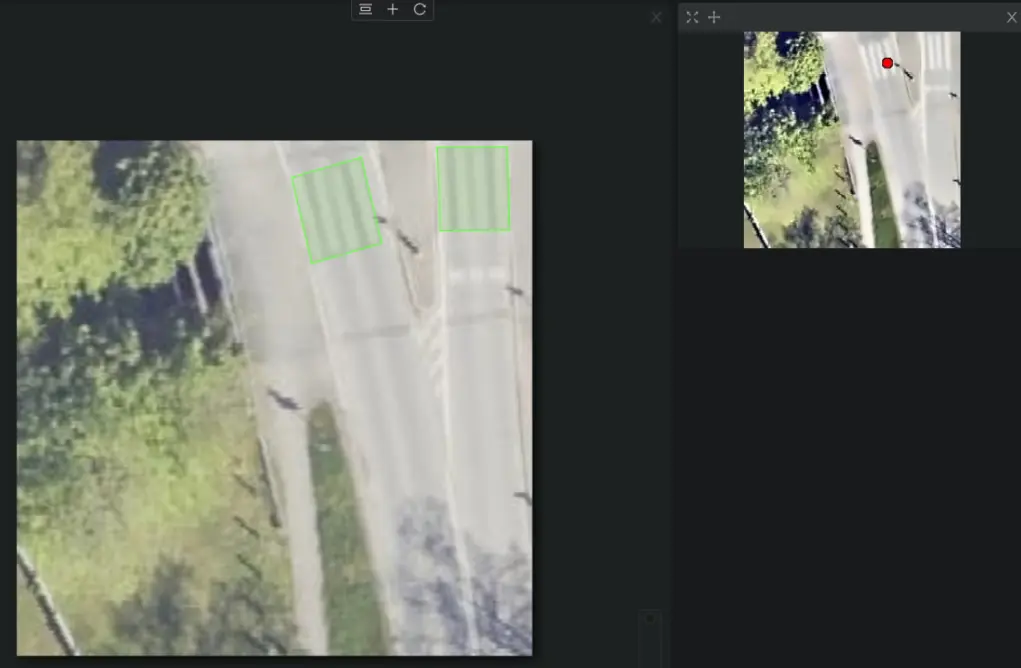
To make the model more robust to variations in crossing appearance, I opted to label crossings with exact polygons rather than simple bounding boxes. How? By augmenting the limited dataset with rotated and skewed crossings. Then, I applied the same transformations to the labeled polygons to obtain the resulting bounding boxes. This approach would not be possible if I labeled the crossings using bounding boxes from the start. Of course, more hand-labeled data would be better, but that would require more time.

The second stage of the process leveraged a Convolutional Neural Network (CNN) for high-quality classification of zebra crossings identified by the YOLO model. Here, the labeling task shifted to a binary classification problem: classifying each image as containing either a zebra crossing at its center or not.
On average, I labeled around 5 crossings per second, resulting in a labeling speed of about 300 crossings per minute - a 50x speedup compared to the YOLO labelling.

I opted for YOLOv8-XS for the area of interest detection model. This lightweight model variant was well-suited for the initial coarse filtering stage, prioritizing speed over quality.
For the CNN classifier, I chose a pre-trained MobileNetV3-Large model and fine-tuned it on the project-specific dataset. This transfer learning approach enabled the CNN to effectively learn the key visual characteristics of zebra crossings while reducing training time.
Both models are able to operate efficiently on a CPU, which was essential for my server setup at the time.
OpenStreetMap is a collaborative project that thrives on the contributions of volunteers around the world. It’s important to ensure the platform’s data quality remains high. To maintain these high standards, I collaborated with the Polish OSM community to establish a target precision of 99.8%. This means that the model could introduce a maximum of 0.2% false positives, marking crossings that don’t exist. The model’s confidence threshold was then set high enough to pass this requirement.
The trained and deployed model achieved a recall of over 90% (I didn’t save the exact number). Meaning, it was able to map over 90% of the detected crossings while keeping the false positive rate strictly below 0.2%.
Over its lifetime, the project successfully mapped around 38,000±2,000 zebra crossings. This Overpass query showcases the majority of imported crossings - those that have not been edited by others since import (due to an Overpass limitation).
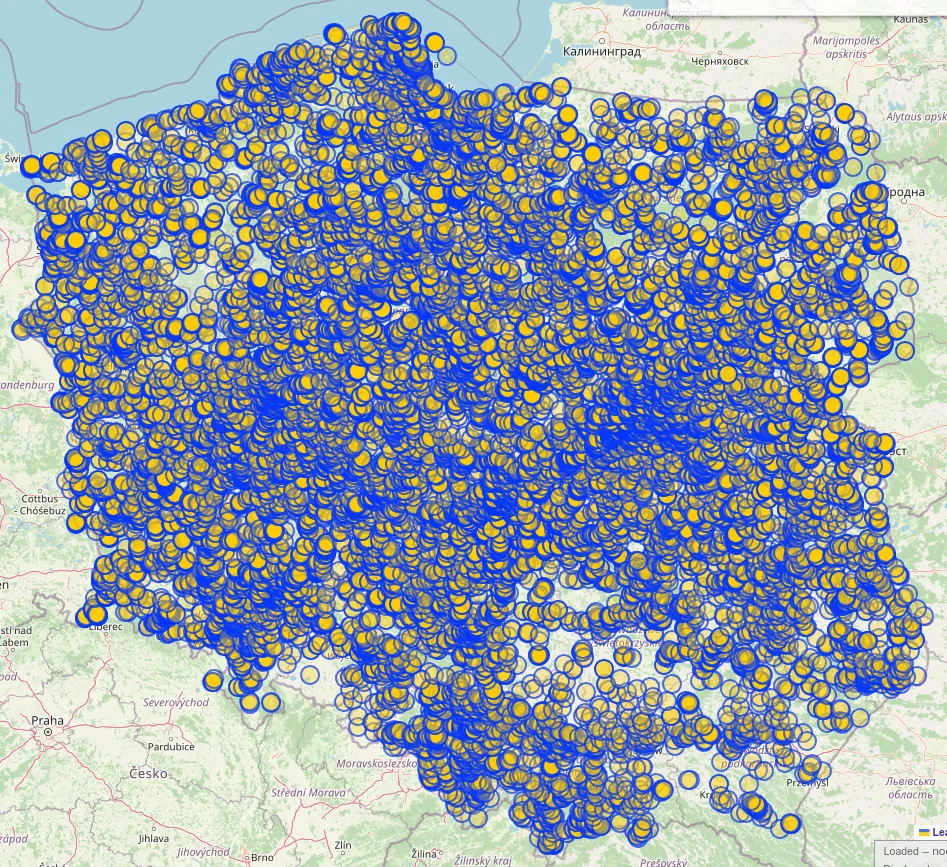
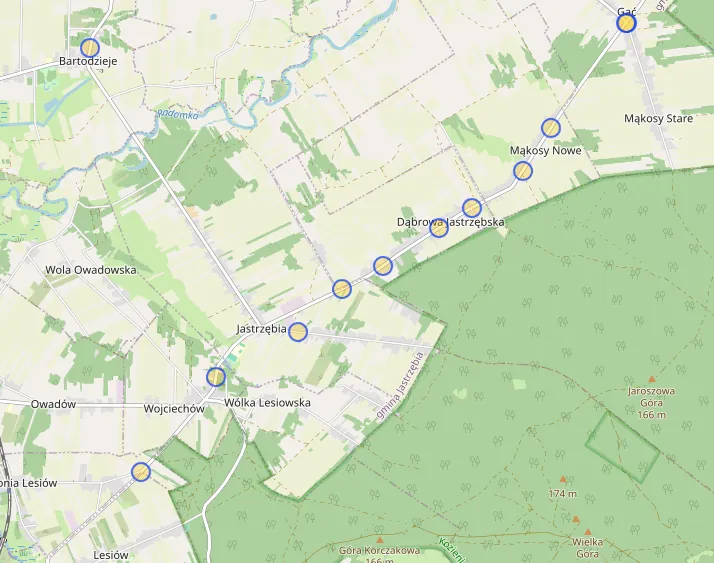
While the project’s overall runtime was approximately three months, this duration was primarily a result of intentional safeguards. Built-in rate limiting slowed down execution to allow human reviewers to oversee the progress. In the event of a substantial failure, the project could be halted and the data reverted, minimizing potential damage. Luckily, that was never necessary.
Overall, I am very satisfied with the results. It was a fun project that let me improve my skills in machine learning, and contribute to the OpenStreetMap community in a more impactful way.
Two-Step Model Approach: Separating the detection and classification tasks into two stages sped up training data preparation substantially. YOLO was used to detect areas of interest with a low confidence threshold, while the CNN was used to classify these regions with high confidence.
CVAT Feels Clunky: While a capable tool, CVAT did feel somewhat clunky to use. In the future, I would consider trying out other labeling tools to see if they offer a smoother experience.
TensorBoard is a Must: Using TensorBoard for model training visualization has let me iterate over the design more effectively. From now on, I will keep it as a must-have tool for all my machine learning projects. It’s a great time saver.
You can find the source code for the project on my GitHub: Zaczero/osm-yolo-crossings. Please note: documentation is poor as this was primarily a personal proof-of-concept. However, if you have questions or need help with a similar project, you can reach out to me.
I would like to thank syntex, an OpenStreetMap contributor, who in later stages of the project helped with data labeling tasks. Their contribution has led to a more accurate final model.